包管理
npm
npm(Node Package Manager)是 Node.js 的默认包管理器,通过中心化的包注册表(如 https://registry.npmjs.org)管理 JavaScript 包的安装和发布。以下是 npm 的主要工作原理:
包注册表 (Registry)
npm使用一个中心化的包注册表,通常位于https://registry.npmjs.org。注册表是一个巨大的 JSON 数据库,包含了所有可用的 npm 包的信息,包括包的名称、版本、依赖关系、作者、许可证等元数据。- 当你运行
npm install <package>命令时,npm会从注册表中获取包的元数据,并根据这些信息下载和安装所需的文件。
依赖管理
npm使用package.json文件来管理项目的依赖关系。这个文件列出了项目所需的包及其版本范围。- 当你运行
npm install命令时,npm会读取package.json文件,解析其中的依赖关系,并从注册表下载和安装这些依赖。 npm会生成或更新package-lock.json文件(或npm-shrinkwrap.json文件),记录每个依赖的具体版本,确保在不同环境中安装的依赖版本一致。
节点模块目录 (node_modules)
npm会在项目的根目录下创建一个node_modules文件夹,用于存放所有安装的依赖包。node_modules文件夹可以包含多个层级的子目录,每个子目录对应一个依赖包及其自身的依赖。- 从
npm3.0 版本开始,引入了扁平化依赖管理机制,尽量将相同版本的依赖包安装在顶层node_modules目录中,避免重复安装。
全局安装
npm支持全局安装包,通常用于安装命令行工具或开发工具。- 全局安装的包会被放置在系统的全局
node_modules目录中,并且会将可执行文件的路径添加到系统的PATH环境变量中,以便直接调用。
扁平化依赖管理
- 从
npm3.0 开始,引入了扁平化依赖管理机制。核心思想是尽量将相同版本的依赖包安装在顶层node_modules目录中,避免重复安装。 - 通过解析依赖树,
npm会尝试合并相同版本的依赖包,减少磁盘空间占用和安装时间。 - 对于那些需要引用顶层依赖的子依赖包,
npm会使用符号链接(symlinks)或直接引用的方式,确保它们能够正确访问所需的依赖包。
- 从
npm 缺点
磁盘空间占用大
npm会为每个项目创建独立的node_modules目录,导致大量重复的依赖包被多次下载和存储,占用大量磁盘空间。
安装速度慢
- 由于
npm需要为每个项目单独下载和安装依赖包,安装过程可能会比较慢,尤其是在依赖树复杂或网络条件不佳的情况下。
- 由于
依赖树复杂
npm的依赖管理机制可能导致复杂的依赖树,多层嵌套的node_modules目录结构使得依赖关系难以管理和理解,有时会导致“依赖地狱”问题。
全局安装管理不直观
- 全局安装的包管理和版本控制不够直观,容易导致版本混乱。
安全性和审计功能有限
- 虽然
npm提供了一些安全性和审计功能(如npm audit),但这些功能相对有限,不如一些现代包管理器(如pnpm)提供的功能强大。依赖审计和安全更新的流程不够自动化,需要用户手动干预。
- 虽然
缓存机制不够高效
npm的缓存机制虽然存在,但不如pnpm等现代包管理器高效。缓存命中率较低,导致重复下载的情况较多,影响安装速度和磁盘空间利用率。
工作区支持较弱
npm的工作区(monorepo)支持相对较弱,管理大型多包项目时不够灵活和高效,导致开发和构建过程复杂。
社区和生态系统问题
- 虽然
npm的社区非常庞大,但也存在包的质量参差不齐、恶意包的存在等问题。依赖包的审核和管理机制不够严格,有时会导致安全漏洞或恶意代码的传播。
- 虽然
通过这些原理和缺点的分析,可以看出 npm 在许多方面仍然是一个强大的包管理器,但在某些方面仍有改进的空间,特别是磁盘空间占用、安装速度、依赖管理、全局包管理、安全性和审计功能等方面。这些不足促使了一些现代包管理器(如 pnpm 和 Yarn)的出现和发展,这些工具在某些方面提供了更好的解决方案。
pnpm
内容寻址存储 (Content-Addressable Storage, CAS)
高效的磁盘空间利用,快速的依赖安装。pnpm 使用内容寻址存储(CAS)来管理依赖包。每个文件根据其内容生成一个唯一的哈希值,并存储在全局缓存中。当项目需要某个依赖时,pnpm 会检查全局缓存中是否存在该哈希值对应的文件。如果存在,则直接使用缓存中的文件;如果不存在,则从远程仓库下载并存储到缓存中。这种方式避免了重复下载和存储相同的文件,从而节省了磁盘空间并加快了安装速度。同时,通过哈希值校验,pnpm 可以确保下载的文件没有被篡改,保证了文件的完整性和安全性。
不会重复安装同一个包。用 npm/yarn 的时候,如果 100 个项目都依赖 lodash,那么 lodash 很可能就被安装了 100 次,磁盘中就有 100 个地方写入了这部分代码。但在使用 pnpm 只会安装一次,磁盘中只有一个地方写入,后面再次使用都会直接使用 hardlink 硬链接。
即使一个包的不同版本。pnpm 也会极大程度地复用之前版本的代码。举个例子,比如 lodash 有 100 个文件,更新版本之后多了一个文件,那么磁盘当中并不会重新写入 101 个文件,而是保留原来的 100 个文件的 hardlink,仅仅写入那一个新增的文件。
依赖链接 (Dependency Linking)
减少磁盘占用,加快安装速度。pnpm 不会将依赖包复制到每个项目的 node_modules 文件夹中,而是通过符号链接(symlinks)将依赖包链接到全局存储中的实际文件。这种方式使得多个项目可以共享同一个依赖包的实例,从而大大减少了磁盘空间的占用,并且安装过程也更快,因为不需要进行大量的文件复制操作。同时,种方式不仅减少了磁盘空间的占用,还提高了环境的隔离性,避免了全局污染和依赖冲突。每个项目都有独立的依赖树,确保了不同项目之间的依赖不会相互影响,从而减少了潜在的安全风险。
并行化下载
加快网络下载速度。pnpm 支持并行下载多个包,可以在同一时间从多个源下载不同的包。通过并行化下载,pnpm 能够更有效地利用网络带宽,减少总的下载时间,尤其是在网络条件较好的情况下效果更加明显。
智能解析算法
最小化不必要的下载和处理。pnpm 使用高效的解析算法来确定需要下载哪些包及其版本。在解析 package.json 文件时,pnpm 会智能地判断哪些依赖已经存在于全局缓存中,哪些需要下载,从而避免不必要的网络请求和文件处理。
支持 monorepo。
pnpm 通过工作区(workspaces)功能,允许在一个 package.json 文件中定义多个包的依赖关系。工作区可以指定一个或多个目录,这些目录中的每个子项目都可以有自己的 package.json 文件,但它们共享同一个根 package.json 文件中的依赖配置。通过这种方式,pnpm 可以确保所有子项目使用相同的依赖版本,避免版本不一致带来的问题。在 Monorepo 中,多个子项目可能会使用相同的依赖包。pnpm 只需要下载一次这些依赖包,并通过符号链接将它们链接到各个子项目的 node_modules 目录中。
安全性高。
之前在使用 npm/yarn 的时候,由于 node_module 的扁平结构,如果 A 依赖 B, B 依赖 C,那么 A 当中是可以直接使用 C 的,但问题是 A 当中并没有声明 C 这个依赖。因此会出现这种非法访问的情况。pnpm 可以解决这种问题,保证了安全性。pnpm 通过严格模式和锁定文件(pnpm-lock.yaml)确保依赖版本的一致性,防止意外的依赖冲突和漏洞;使用内容寻址存储(CAS)和哈希值校验来验证文件的完整性和防止恶意文件篡改;提供内置的依赖审计功能(pnpm audit)检测已知的安全漏洞并提供修复建议,从而全面提高项目的安全性。
npm vs npx
npm install 流程与原理
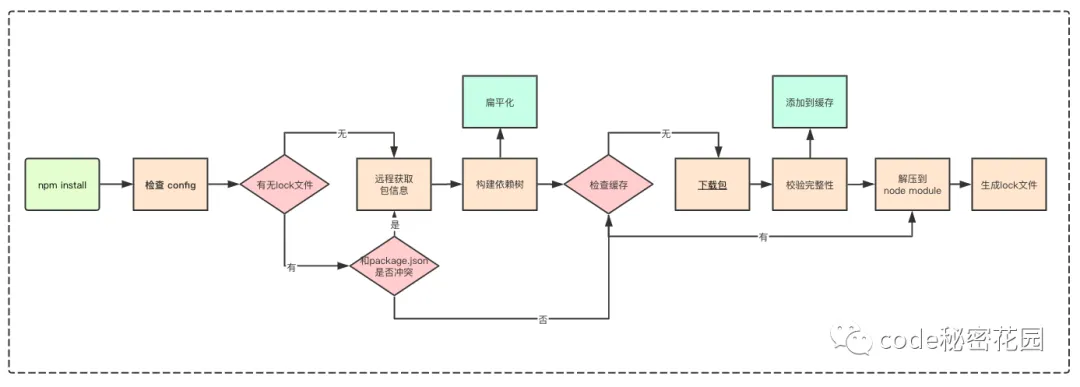
npm install 的工作原理可以分为几个主要步骤,这些步骤确保了项目的依赖能够被正确地解析、下载和安装。
检查
.npmrc文件。npm会首先读取配置文件来确定一些重要的设置,比如认证信息、注册表地址等。配置文件的优先级顺序如下:- 项目级别的
.npmrc文件(位于项目根目录) - 用户级别的
.npmrc文件(通常位于用户主目录) - 全局级别的
.npmrc文件(通常位于 npm 安装路径下) - npm 内置的
.npmrc文件
- 项目级别的
检查锁文件。
npm会检查项目中是否存在package-lock.json或npm-shrinkwrap.json文件。这些文件用于锁定项目依赖的确切版本,以保证不同环境中安装的依赖一致。如果不存在锁文件:npm 会从远程仓库获取最新的包信息。根据 package.json 中定义的依赖关系构建依赖树。在构建依赖树时,所有依赖(无论是直接依赖还是间接依赖)都会尽量放置在 node_modules 的根目录下,以减少嵌套层级。如果发现重复的模块,npm 会检查现有模块的版本是否满足新模块的版本要求。如果满足,则不再重复安装;如果不满足,则会在适当的 node_modules 子目录中安装所需版本。
如果存在锁文件:npm 会先检查 package.json 中的依赖版本与锁文件中的记录是否有冲突。如果没有冲突,npm 将直接使用锁文件中指定的版本进行安装,跳过从远程仓库获取最新包信息和构建依赖树的步骤。
从缓存或远程仓库获取包
- 缓存中存在所需版本的包:直接从缓存中复制包到
node_modules。 - 缓存中不存在所需版本的包:从远程仓库下载包。下载完成后,
npm会对包进行完整性校验。如果校验失败,npm会重新下载直到成功。校验通过后,将包复制到缓存目录,并解压到node_modules中相应的路径。
- 缓存中存在所需版本的包:直接从缓存中复制包到
生成锁文件。如果之前没有锁文件,或者在安装过程中对依赖进行了更新,
npm会在安装完成后生成或更新package-lock.json文件,以记录当前安装的所有依赖及其确切版本。
npx 流程与原理
npx 是 npm 提供的一个命令行工具,它的设计目的是简化命令的执行和包的临时安装。
- 自动安装缺失的包:如果某个命令需要的包尚未安装,npx 会自动从 npm 仓库下载并安装该包。
- 无需全局安装:可以在不全局安装包的情况下运行命令,避免了全局污染和版本冲突。
- 临时环境:适合在临时环境中运行一次性命令,如脚本或工具。
- 简化命令:可以直接运行包中的命令,而不需要显式地指定路径或版本。
首先,npx 会在当前项目的 node_modules/.bin 目录中查找命令。如果找不到,npx 会检查全局安装的包。如果仍然找不到,npx 会尝试从 npm 仓库下载并安装所需的包。一旦找到或安装了所需的包,npx 会执行该命令。执行过程中,npx 会传递所有额外的参数给命令。如果 npx 临时安装了包,执行完命令后,这些临时安装的包会被删除(除非指定了 --no-install 选项)。